We dive deep into the world of AI to understand how it can be used for optimal training and performance.
We dive deep into the world of AI to understand how it can be used for optimal training and performance.

We dive deep into the world of AI to understand how it can be used for optimal training and performance.
We dive deep into the world of AI to understand how it can be used for optimal training and performance.

Understanding when and how to introduce HIIT can make all the difference in an athlete’s ability to absorb training and optimize performance.

In part 3 of our series on movement literacy for cyclists, Dr. Stacey Brickson delves into stability and strength to make you a healthier cyclist.

In this multi-part series, Dr. Stacey Brickson details several tools built on a hierarchy of mobility, flexibility, stability, and strength, designed to make you a healthier cyclist.
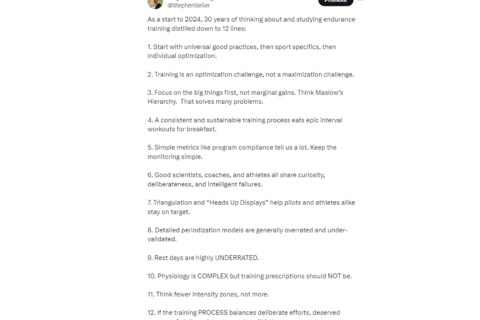
After 30 years of studying exercise endurance training, Dr. Seiler distills it all into 12 fundamental practices.